发布日期:2025-01-09 02:09 点击次数:53

1.什么是openMind?金发大奶
openMind 是一个开源的深度学习开荒套件,包含 openMind Library 和 openMind Hub Client,通过爽直易用的API撑握模子预锻真金不怕火、微调、推理等历程。openMind Library通过一套接口兼容PyTorch和MindSpore等主流框架,同期原生撑握昇腾NPU经管器
细目见详尽|魔乐社区
2.怎样体验?
2.1.环境设置
需要设置 python , numpy, torch, openmind, openmind_hub 。
笔者的电脑是MAC,是以这里仅爽直提供MAC设置上述环境的门径。
装配python
淌若你的电脑也曾装配了homebrew,掀开限度台,输入一下号召即可
brew install python3
淌若你的电脑还莫得装配 homebrew, 不错使用官网给的号召装配
也不错使用国内镜像去装配
/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"
装配 numpy, torch, openmind, openmind_hub
pip install numpy
其他号召与装配numpy疏浚,这里不再赘述。
2.2. 模子下载(huggingface)
hugging face 这个开源平台提供了无数预锻真金不怕火模子,不错从中遴荐可爱的模子,这里以MiniLM为例
hugging face搜索microsoft/MiniLM-L12-H384-uncased,然后在界面上找到 git 聚拢将仓库拷贝到土产货
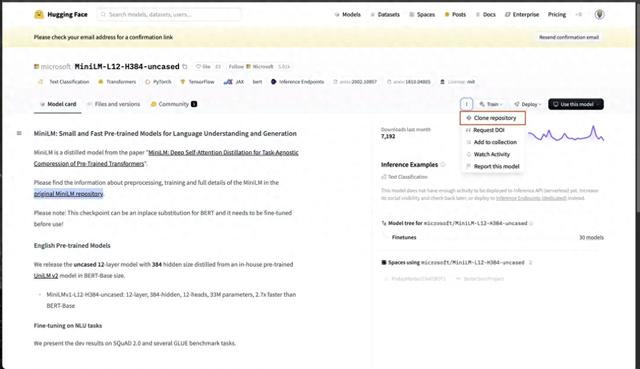
git clone https://huggingface.co/sentinet/suicidality
2.31. 模子上传
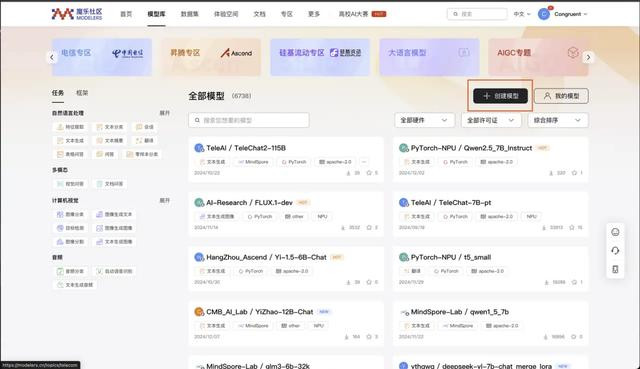
魔乐社区撑握资源存储和分享,咱们不错将土产货模子上传至魔乐社区存储与分享,共同构建AI开源生态。一般为了考证模子可用性将模子 clone 到土产货后咱们会不错遴荐在土产货对模子进行测试,而魔乐社区提供了模子测试,方便你下载的模子是经过测试可使用的,大大松开了大规模模子下载到土产货后的模子可用性。也不错遴荐将模子上传到魔乐社区以后通过魔乐社区的openmind 套件进行测试,需要属观点是,使用魔乐社区的openmind套件进行测试需要提前写好测试剧本以及设置文献,这里仅先容后者。
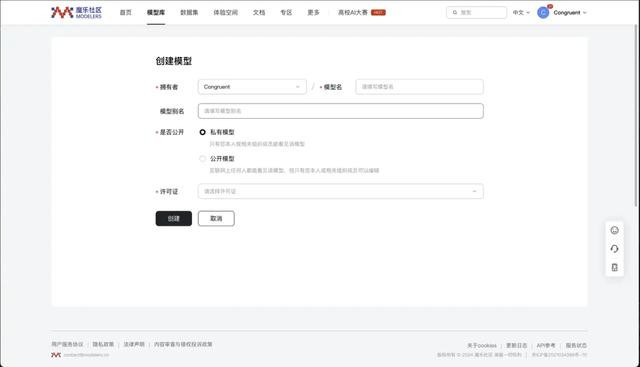
底下将先容怎样将模子上传至魔乐社区,并在进行模子可用性测试。最初需要在魔乐社区创建好你的模子仓库,创建递次也相配爽直,首页遴荐创建模子后填写好仓库称呼即可。
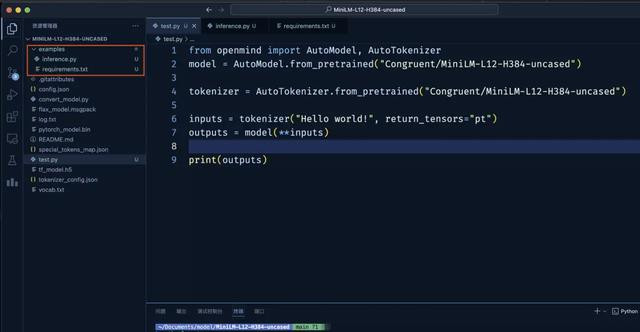
模子可用性测试剧本必须包含以下两个文献:
requirements.txt:该剧本运行需设置的相应module (淌若莫得需要装配的依赖,请创建一个空的requirements.txt文献)。
inference.py: 基于openMind Library的可运行的推理剧本。
且上述两个文献需要位于 examples 目次下,examples目次需要新建在根目次下。
咱们新建好上述需要的测试文献后,就不错驱动上传了,这里提供了一个提交剧本(仅供参考)
from openmind_hub import upload_folder
# 使用upload_folder向仓库中上传文献夹。
# token:对观点仓库具有可写权限的造访令牌,必选。
# folder_path:要上传的土产货文献夹的旅途,必选。
# repo_id:观点仓库,必选。
# 若需对上传的文献类型进行过滤,不错使用allow_patterns和ignore_patterns参数,详见upload_folder。
print("Starting upload_folder...")
try:
upload_folder(
token="c90ac22f50a12262da562c11234f9077af73966f",
folder_path=r"/Users/congruent/Documents/model/MiniLM-L12-H384-uncased",
repo_id="Congruent/MiniLM-L12-H384-uncased"
)
print("Upload successful.")
except Exception as e:
print(f"An error occurred: {e}")
在上传过程中,可能会出现

如图所示诞妄,这是由于 READMD.md 中莫得指定 license 导致的,在文献中补充后再次提交即可。
详确的条件见可用性测试 | 魔乐社区
2.42 体验空间
在你上传好我方的模子并通过可用性测试之后,你就不错用我方的模子搭建多样作事以及应用来大约使用吗,魔乐社区提供了体验空间的功能来方便使用者搭建我方的作事。
这里我用MiniLM来搭建了一个爽直的问答系统来作念演示
在搭建问答系统之前需要先将魔乐社区我方上传的模子下载进哄骗用,魔乐社区提供了两种格式操作,一种是通过openmind,另一种则是通过git,在首页中找到我方上传的模子,点击下载模子。
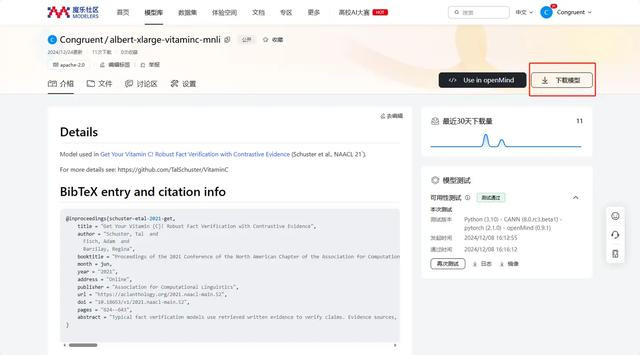
这个界面上会给出两种格式的操作,使用openmind下载凯旋将对应的语句镶嵌代码即可,使用git则需要将语句粘贴到末端运行。
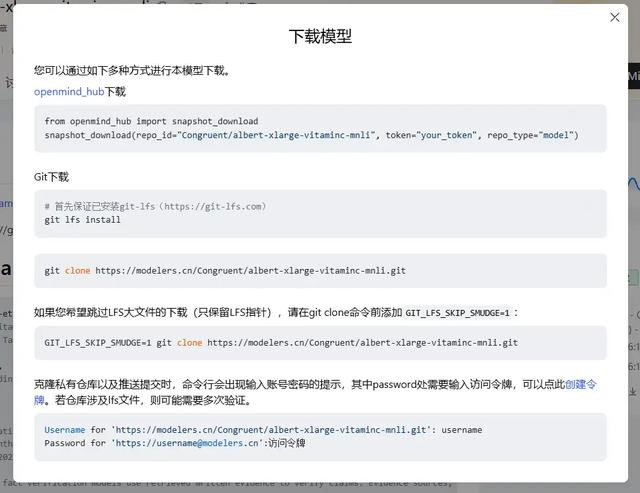
先遴荐创建一个体验空间
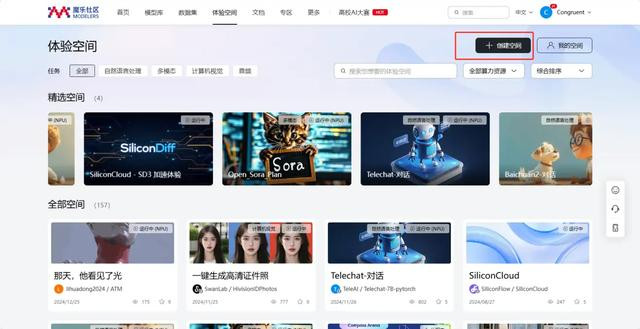
2.在这个界面遴荐相应的设置,由于这里笔者的模子测试很爽直,是以CPU的算力就也曾豪阔了,有其他需求不错自行遴荐。环境遴荐了Python3.9+pytorch+openmind的搭配,这里自行遴荐即可。
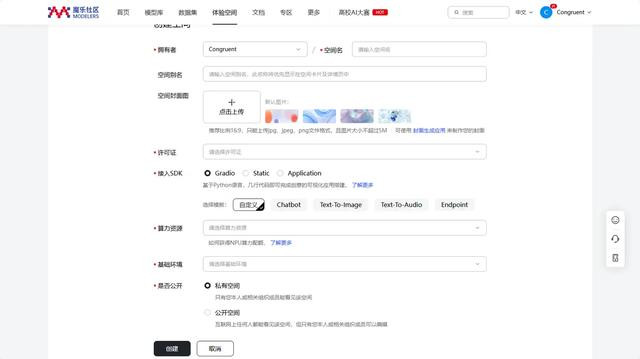
3.创建完成后是一个空的git仓库,按照评释将仓库克隆到土产货,然后在这个仓库内创建两个文献,第一个文献是 app.py ,即用于使用 gradio 进行体验空间的运行,第二个requirements.txt 则是一些设置
这里给出笔者的 miniLm 的 app.py
import gradio as gr
import torch
from openmind import AutoModel, AutoTokenizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 加载 MiniLM 模子和分词器
model_name = "Congruent/MiniLM-L12-H384-uncased"
model = AutoModel.from_pretrained(model_name)
激情与放荡tokenizer = AutoTokenizer.from_pretrained(model_name)
qa_pairs = [
{"question": "What is the capital of France?", "answer": "Paris"},
{"question": "Who is the CEO of Apple?", "answer": "Tim Cook"},
{"question": "How many legs does a spider have?", "answer": "Eight"}
]
def encode_question_and_answers(question, answers, tokenizer, model):
# 编码问题
inputs = tokenizer(question, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad:
question_outputs = model(**inputs)
question_embedding = torch.mean(question_outputs.last_hidden_state, dim=1).detach.cpu.numpy # 一维数组
# 编码谜底
answer_embeddings = []
for answer in answers:
inputs = tokenizer(answer, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad:
answer_outputs = model(**inputs)
answer_embedding = torch.mean(answer_outputs.last_hidden_state, dim=1).squeeze.detach.cpu.numpy # 确保是一维数组
answer_embeddings.append(answer_embedding)
# 凯旋将列表疗养为 NumPy 数组,它将是一个二维数组(样本数 x 镶嵌维度)
answer_embeddings_array = np.array(answer_embeddings)
return question_embedding, answer_embeddings_array
def find_best_answer(question, all_qa_pairs, tokenizer, model):
answers = [qa_pair["answer"] for qa_pair in all_qa_pairs]
question_embedding, answer_embeddings = encode_question_and_answers(question, answers, tokenizer, model)
# 蓄意同样度时,确保 question_embedding 是二维的
similarities = cosine_similarity(question_embedding[0].reshape(1, -1), answer_embeddings)
best_index = np.argmax(similarities)
return all_qa_pairs[best_index]["answer"]
# # 测试问答系统
# test_questions = [
# "What is the capital of France?",
# "Who leads Apple?",
#
def query(question):
return find_best_answer(question, qa_pairs, tokenizer, model)
app = gr.Interface(fn=query, inputs="text", outputs="text")
app.launch
Def query上头的部分是本人的MiniLM的模子应用部分,行将事前准备的语料用于向量化匹配,query下的 app 两行则是 gradio的使用,具体稽察干系文档进哄骗用
而关于reqirement.txt则相配爽直,末端输入
cat > requirements.txt
即可完成。
上述创建完成后,使用 git push 提交到仓库的main分支即可,tips:提交之前难忘在魔乐社区创建令牌以及使用git 提交对应的文献和提交信息到土产货后再push回仓库。
终末你就不错在体验空间中看到你的模子啦。
 金发大奶
金发大奶